hina.mesoscale
Tutorial
The mesoscale module provides methods for clustering one set of nodes in a heterogeneous interaction network based on their shared interactions with nodes in another node set. The clustering methods employed automatically learn the number of clusters from the heterogeneity in the interaction data to find the mesoscale representation. This module can incorporate other algorithms for understanding the mesoscale structure of interaction networks.
Currently, the module contains the clustering.py file, which includes:
hina_communities: Identifies communities in a bipartite/tripartite network by optimizing a Minimum Description Length (MDL) objective that modifies the microcanonical stochastic block model for the intended clustering task.
The MDL hina community detection method hina_communities (custom developed for the HINA package) finds a community partition of the nodes in the first node set using an information theoretic objective function that automatically selects for the optimal number of clusters. This objective scores a partition of the nodes according to how well it allows for the transmission of the bipartite/tripartite graph while exploiting redundancies in the edges coming from members of the same community. It develops a description length objective by breaking the information transmission process into three steps: (1) Transmit community labels of nodes in the first set; (2) Transmit total edge weight contributions from each of the communities; (3) Transmit weights of each edge from Set 1 to Set 2 (the graph) given the constraints imposed by (1) and (2). Following these steps, the objective we use is:
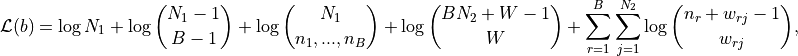
- where:
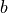 is a partition of the nodes in the first node set into
is a partition of the nodes in the first node set into 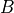 non-empty communities such that
non-empty communities such that 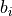 is the community of node
is the community of node 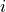
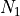 and
and 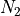 are the sizes of the first node set and second node set respectively
are the sizes of the first node set and second node set respectively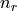 is the size of community
is the size of community 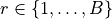
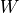 is the total weight of the edges in the bipartite/tripartite graph
is the total weight of the edges in the bipartite/tripartite graph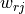 is the total weight of the edges from nodes in community
is the total weight of the edges from nodes in community  to node
to node 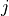 in the second node set
in the second node set
The method optimizes this MDL objective approximately using a fast agglomerative scheme in which we start with every node in its own cluster and iteratively merge the pair of communities that produces the greatest decrease to the description length until all nodes are grouped together. Afterwards, we scan over all solution candidates to identify the MDL-optimal partition.
Function |
Description |
|---|---|
Identifies bipartite/tripartite communities by optimizing the MDL objective. |
Reference
Description: Optimizes a Minimum Description Length (MDL) objective to identify communities in a bipartite/tripartite network. The MDL objective quantifies the trade-off between the complexity of the community structure and the efficiency of encoding the network information. The algorithm begins by assigning each node in the first node set to its own community, then iteratively merges communities that produce the greatest decrease in the total description length. The optimal partition is chosen either automatically or by fixing the number of communities via the fix_B parameter.
Parameters:
-
G: A bipartite network represented as a NetworkX graph with weighted edges.
- Edges are expected to be represented as tuples
(i, j, w), whereiandjare node labels andwis a positive integer.
- Edges are expected to be represented as tuples
-
fix_B: (Optional) An integer specifying a fixed number of communities.
Default:
None.- If set to
None, the algorithm automatically determines the optimal number of communities. - If an integer is provided, the nodes will be partitioned into exactly that many communities.
- If set to
- Returns:
dict: A dictionary containing:
number of communities: The number of communities detected.node communities: A dictionary mapping each node (as a string) to its community label.community structure quality value: A float representing the compression ratio (i.e. the inferred description length divided by the naive description length).updated graph object: The original input graph updated with a node attribute (e.g.,communities) indicating each node’s community assignment.sub graphs for each community: A dictionary where keys are community labels and values are the corresponding subgraphs containing nodes of that community.For tripartite networks, an additional key:
object-object graphs for each community: A dictionary mapping community labels to projected graphs of object interactions within each community.
Demo
Example Code
This example demonstrates how to use hina_communities for clustering nodes in a bipartite network.
Step 1: Import necessary libraries
import pandas as pd
from hina.construction import get_bipartite
from hina.mesoscale import hina_communities
Step 2: Define the dataset
A dataset containing student-task interactions:
df = pd.DataFrame({
'student': ['Alice', 'Bob', 'Alice', 'Charlie'],
'object1': ['ask questions', 'answer questions', 'evaluating', 'monitoring'],
'object2': ['tilt head', 'shake head', 'nod head', 'nod head'],
'group': ['A', 'B', 'A', 'B'],
'attr': ['cognitive', 'cognitive', 'metacognitive', 'metacognitive']
})
Step 3: Construct the bipartite network representation
We create a bipartite network representation of the interactions between students and objects in the ‘object1’ category, adding the additional attribute ‘attr’ storing object codes.
B = get_bipartite(df,student_col='student', object_col='object1', attr_col='attr', group_col='group')
Step 4a: Compute bipartite communities using MDL optimization
We identify communities in the bipartite network by minimizing the MDL objective.
result_no_fix = hina_communities(B)
print("Community Summary (No Number of Community Fixing):\n", result_no_fix,'\n')
Step 4b: Apply clustering with a fixed number of clusters
If desired, we can fix the number of clusters manually.
result_fix = hina_communities(B, fix_B=2)
print("Community Summary (Number of Two Community Fixing):\n", result_fix,'\n')
Example Output
Community Summary (No Number of Community Fixing):
{'number of communities': 3,
'node communities': {'Charlie': 0, 'Bob': 1, 'Alice': 2},
'community structure quality value': 1.0,
'updated graph object': <networkx.classes.graph.Graph object at 0x31870bd40>,
'sub graphs for each community': {0: <networkx.classes.graph.Graph object at 0x318709910>, 1: <networkx.classes.graph.Graph object at 0x31870b6b0>, 2: <networkx.classes.graph.Graph object at 0x3187086b0>}}
Community Summary (Number of Two Community Fixing):
{'number of communities': 2,
'node communities': {'Charlie': 0, 'Bob': 0, 'Alice': 1},
'community structure quality value': 1.0732048281404236,
'updated graph object': <networkx.classes.graph.Graph object at 0x31870bd40>,
'sub graphs for each community': {0: <networkx.classes.graph.Graph object at 0x318708860>, 1: <networkx.classes.graph.Graph object at 0x31870b6e0>}}
Paper Source
If you use this function in your work, please cite:
Feng, S., Gibson, D., & Gasevic, D. (2025). Analyzing students’ emerging roles based on quantity and heterogeneity of individual contributions in small group online collaborative learning using bipartite network analysis. Journal of Learning Analytics, 12(1), 253–270.